🔥[2025-02-27] Introducing WorldModelBench, a comprehensive benchmark for world model capacities' evaluation! 🚀
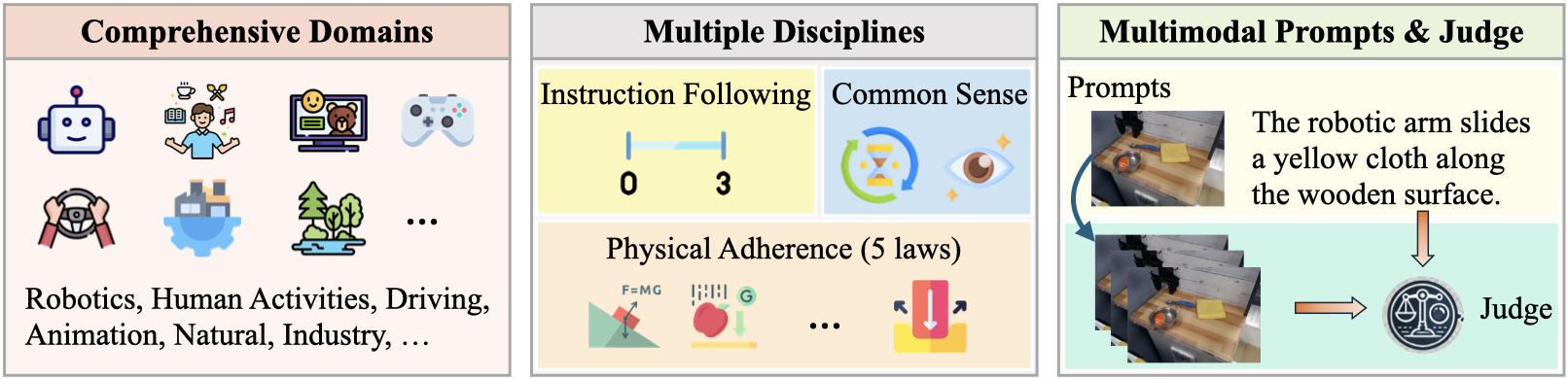
We introduce WorldModelBench, a benchmark designed to evaluate the world modeling capabilities of video generation models across 7 application-driven domains and 56 subdomains. WorldModelBench offers two key advantages: (1) Detection of nuanced world modeling violations: By incorporating instruction following and physics adherence dimensions, our benchmark detects subtle violations, such as irregular changes in object size that breach the mass conservation law — issues often overlooked by existing benchmarks. (2) Alignment with large-scale human preferences: We crowd-source 67K human labels to accurately measure 14 frontier models. Leveraging these high-quality human annotations, we fine-tune a 2B multimodal judger to automate the evaluation procedure, achieving 8.6% higher average accuracy in predicting world modeling violations compared to GPT-4o. We believe WorldModelBench will stimulate the community to build next-generation world models towards expert world simulators.
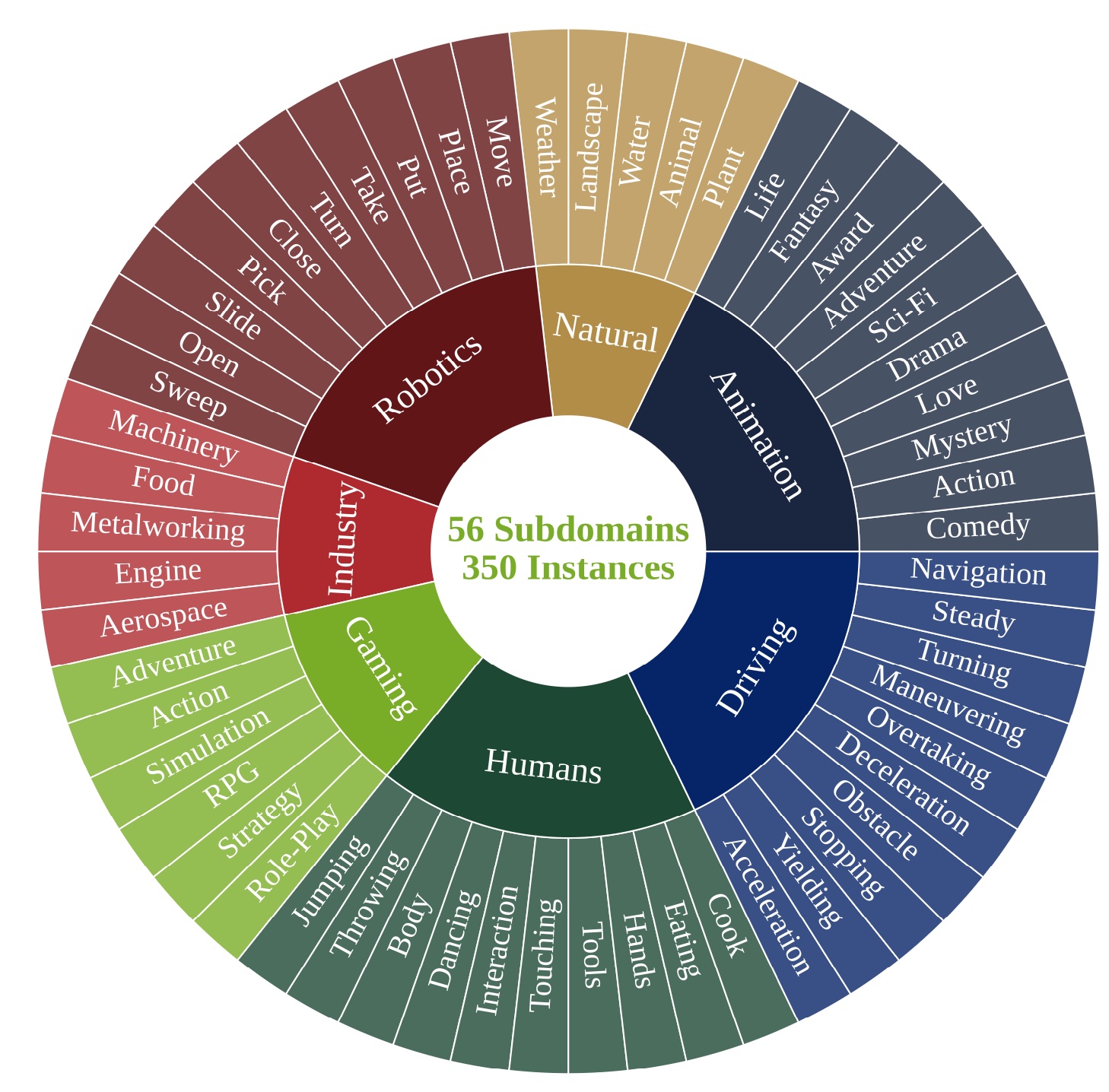
We introduce WorldModelBench, a benchmark designed to assess the world modeling capacities of video generation models across multiple disciplines and diverse application domains. This benchmark includes real-world application domains such as Robotics, Driving, Industry, Human Activities, Gaming, Animation, and Natural, along with detailed subdomains illustrated in the figure. Each domain features 50 carefully curated prompts, comprising a text description and an initial video frame, tailored for video generation. These prompts were meticulously collected by a team of college students (including coauthors) from existing datasets.
WorldModelBench is designed to measure three essential capacities in video generation models: Instruction Following, Common Sense, and Physical Adherence. Our aim is to evaluate how well these models can follow the instructions and reflect the real-world physics.
Specifically, for Instruction Following, we evaluate whether the objects, subjects and their intended moitons align with the given instructions. For Common Sense, we assess both temporal consistency and overall visual quality. For Physical Adherence, we investigate the 5 most common physical hallucinations observed in video generation models, as shown in the gallery below.

Newton’s First Law violation: motion without external force

Solid mechanics violation: irregular deformation

Fluid mechanics violation: unnatural liquid flow

Impenetrability violation: objects intersect unnaturally

Gravity violation: inconsistent behavior under gravity
To clearly highlight the distinction between our WorldModelBench and other existing benchmarks, we providea detailed comparison in the table below. From the Metrics perspective, prior benchmarks are heavily focused on visual quality and instruction following. In contrast, our benchmark emphasizes assessing video generation based on its adherence to real-world physical laws. Previous benchmarks often rely on implicit representation similarity or sparse human labels. In comparison, our benchmark involves a fine-grained human-aligned judge, ensuring a more precise and reliable assessment of video generation results. This focus on physical accuracy and fine-grained judgment sets WorldModelBench apart.
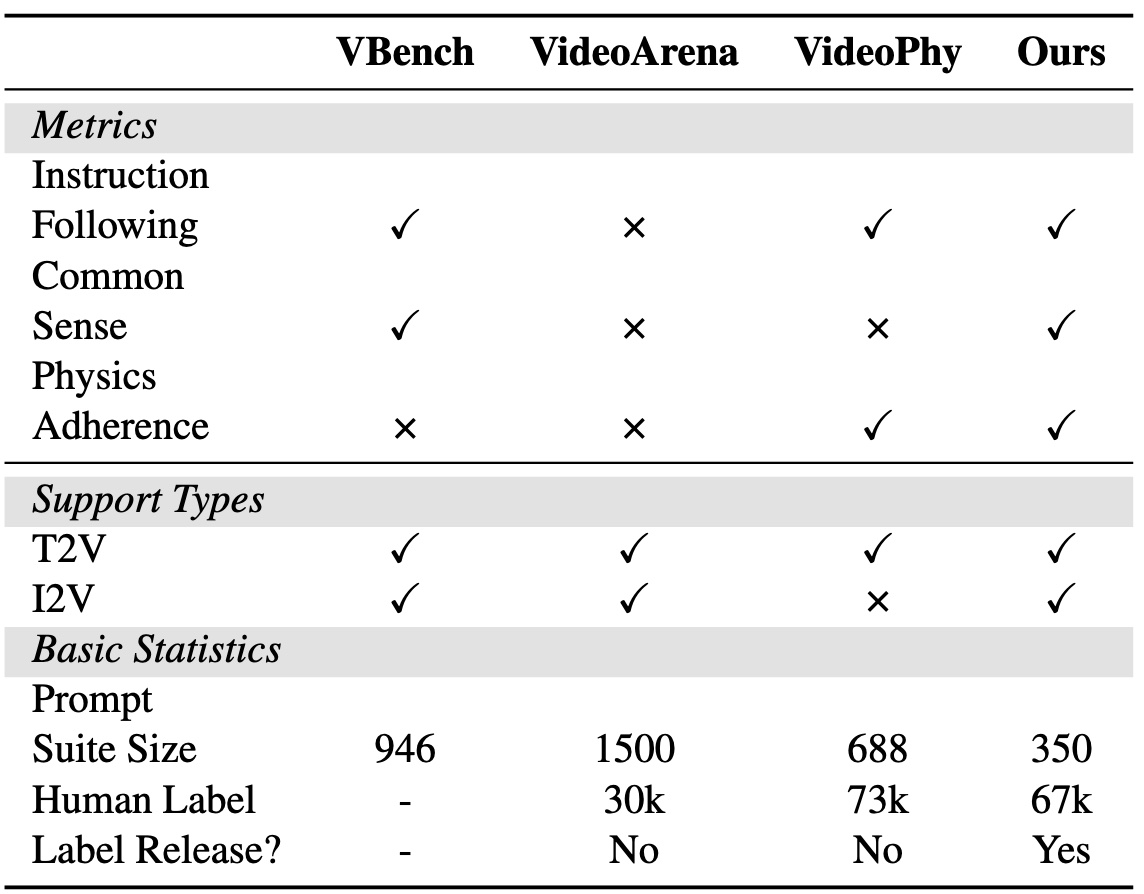
Comparison of WorldModelBench with other common benchmarks. WorldModelBench has comprehensive criteria and human-aligned judge, ensuring robust assessment
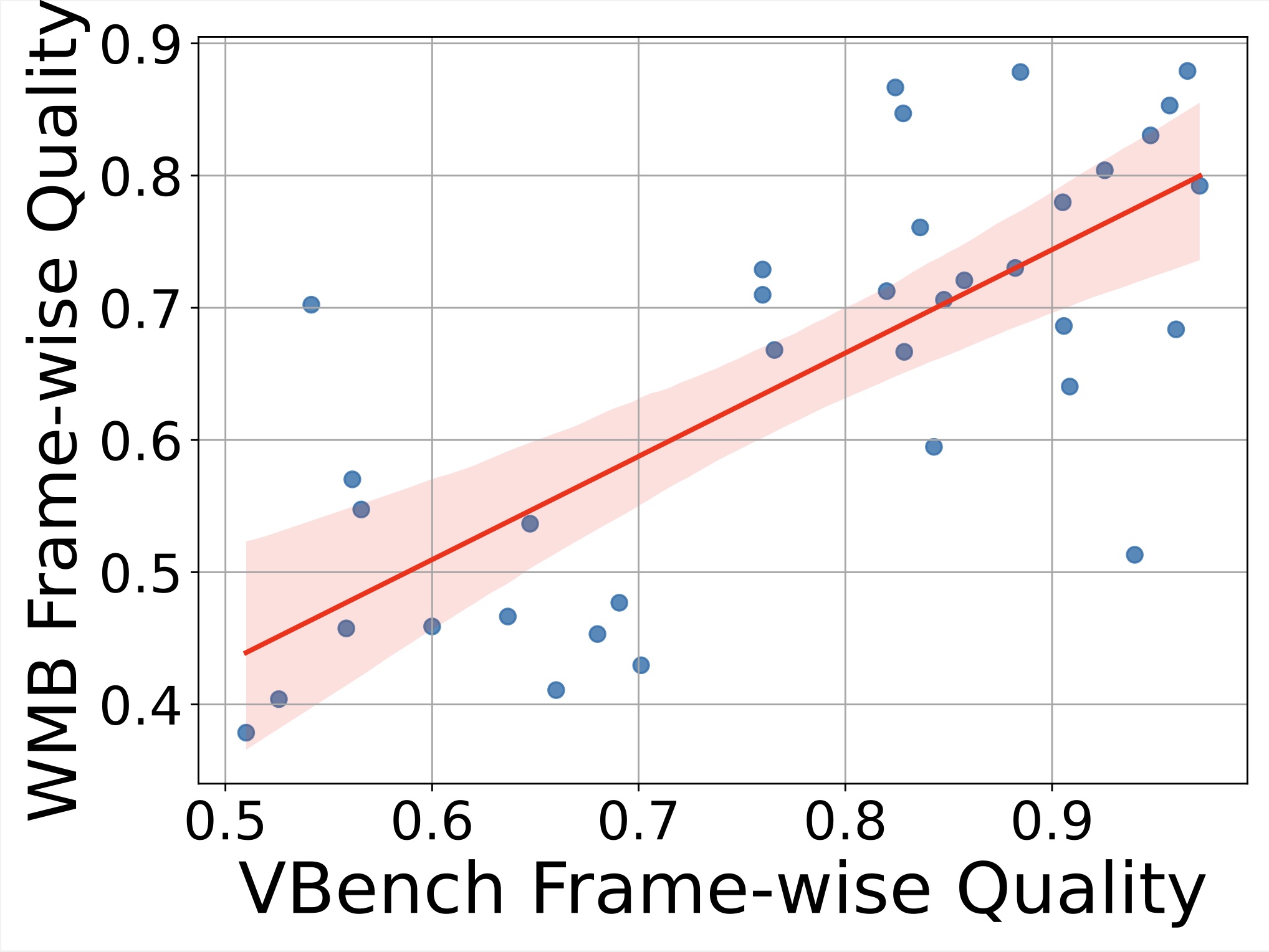
Frame-wise quality correlation between WorldModelBench and VBench
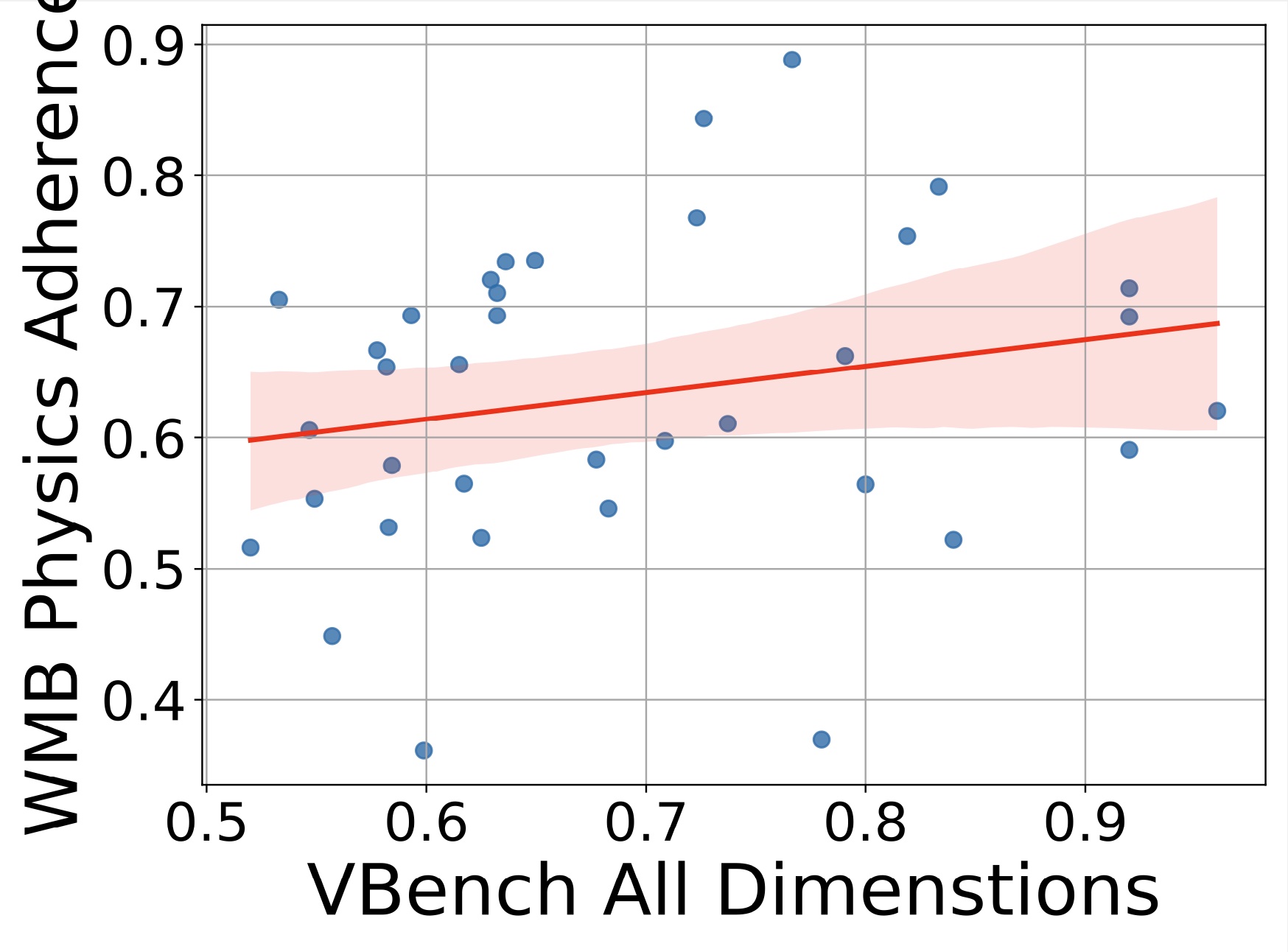
Physics adherence correlation between WorldModelBench and VBench
We evaluate various models including LLMs and LMMs. In each type, we consider both closed- and open-source models. Our evaluation is conducted under a zero-shot setting to assess the capability of models to generate accurate answers without fine-tuning or few-shot demonstrations on our benchmark. For all models, we use the default prompt provided by each model for multi-choice or open QA, if available. If models do not provide prompts for task types in MMMU, we conduct prompt engineering on the validation set and use the most effective prompt for the later zero-shot experiment.
Click on Instruction Following, Physics Adherence or Common Sense to expand detailed results.
| Reset | Instruction Following | Physics Adherence | Common Sense | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Size | Date | Overall | Level 1 | Level 2 | Level 3 | Overall | Newton | Deformation | Fluid | Penetration | Gravity | Overall | Frame-wise | Temporal | Total Score |
Overall results of different models on the WorldModelBench leaderboard. The best-performing model in each category is in-bold, and the second best is underlined. *: results provided by the authors.
@inproceedings{Li2025WorldModelBench,
title={WorldModelBench: Judging Video Generation Models As World Models},
author={Dacheng Li and Yunhao Fang and Yukang Chen and Shuo Yang and Shiyi Cao and Justin Wong and Michael Luo and Xiaolong Wang and Hongxu Yin and Joseph E. Gonzalez and Ion Stoica and Song Han and Yao Lu},
year={2025},
}